Our research has been accepted for publication in IEEE Robotics and Automation Letters (RA-L), 2026.
Abstract
Framework
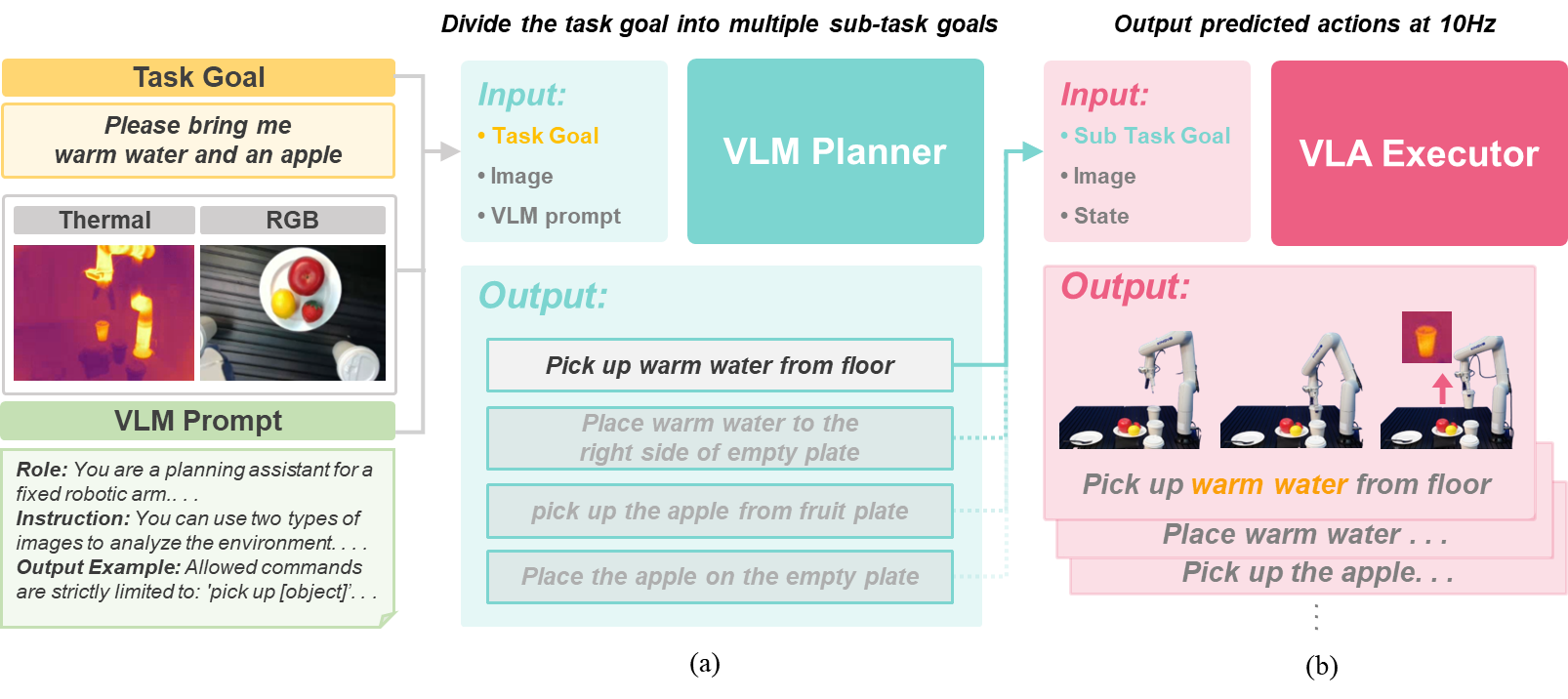
The ThermoAct framework proposed in this study consists of a Vision-Language Model (VLM) that performs reasoning and planning based on user commands and environmental information, and a Vision-Language-Action (VLA) module that executes robot control commands based on this plan. The VLM takes visual inputs, including thermal data, and a natural language instruction to generate a low-level action plan tailored to the situation. Subsequently, the VLA module controls the robot in real time based on the decomposed plan and the corresponding inputs.
Experiment
All tasks were designed to require the successful completion of not only temperature-aware sub-tasks but also everyday sub-tasks (e.g., clearing unused cables and placing an apple on a plate). The sub-tasks decomposed by the VLM Planner follow a standardized format, aligning with protocols used in recent VLM-based robotic planning.
Tasks 1 to 3 were designed to evaluate whether the robot could act more intelligently by utilizing thermal information in daily scenarios, such as handing over a cup of warm water or giving a cold can of soda.
Tasks 4 and 5 were designed to verify the utility of thermal information in safety-related situations, such as picking up an overheated battery, turning off a hot hair straightener, and organizing the nearby power strip.
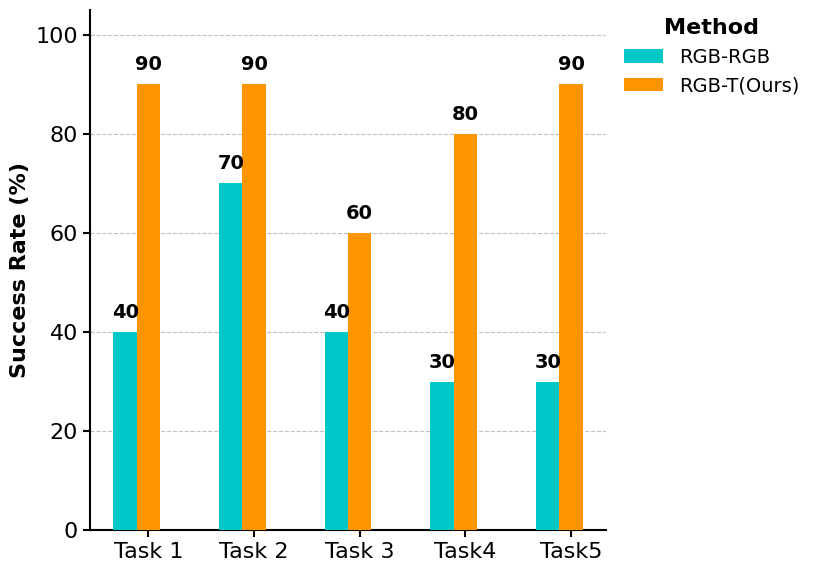
Figure 3: Task design and VLM planning protocol.
Real-World Experiments
Task 2: Give me a cold coke (w/ cold coke)
Task 2: Give me a cold coke (w/o cold coke)
Task 3: Select the appropriate cup (teabag)
Task 3: Select the appropriate cup (lemon)
Task 4: Pick up overheated battery
Task 4: Pick up overheated battery
Task 5: Organize space near power strip
Task 5: Organize space near power strip
Citation
@ARTICLE{11456510,
author={Son, Young-Chae and Ko, Dae-Kwan and Choi, Yoon-Ji and Lim, Soo-Chul},
journal={IEEE Robotics and Automation Letters},
title={ThermoAct: Thermal-Aware Vision-Language-Action Models for Robotic Perception and Decision-Making},
year={2026},
volume={11},
number={5},
pages={6106-6113},
keywords={Robots;Robot sensing systems;Cameras;Robot vision systems;Visualization;Cognition;Planning;Grippers;Wrist;Training;AI-Enabled Robotics;AI-based methods;task planning},
doi={10.1109/LRA.2026.3678130}}