Abstract
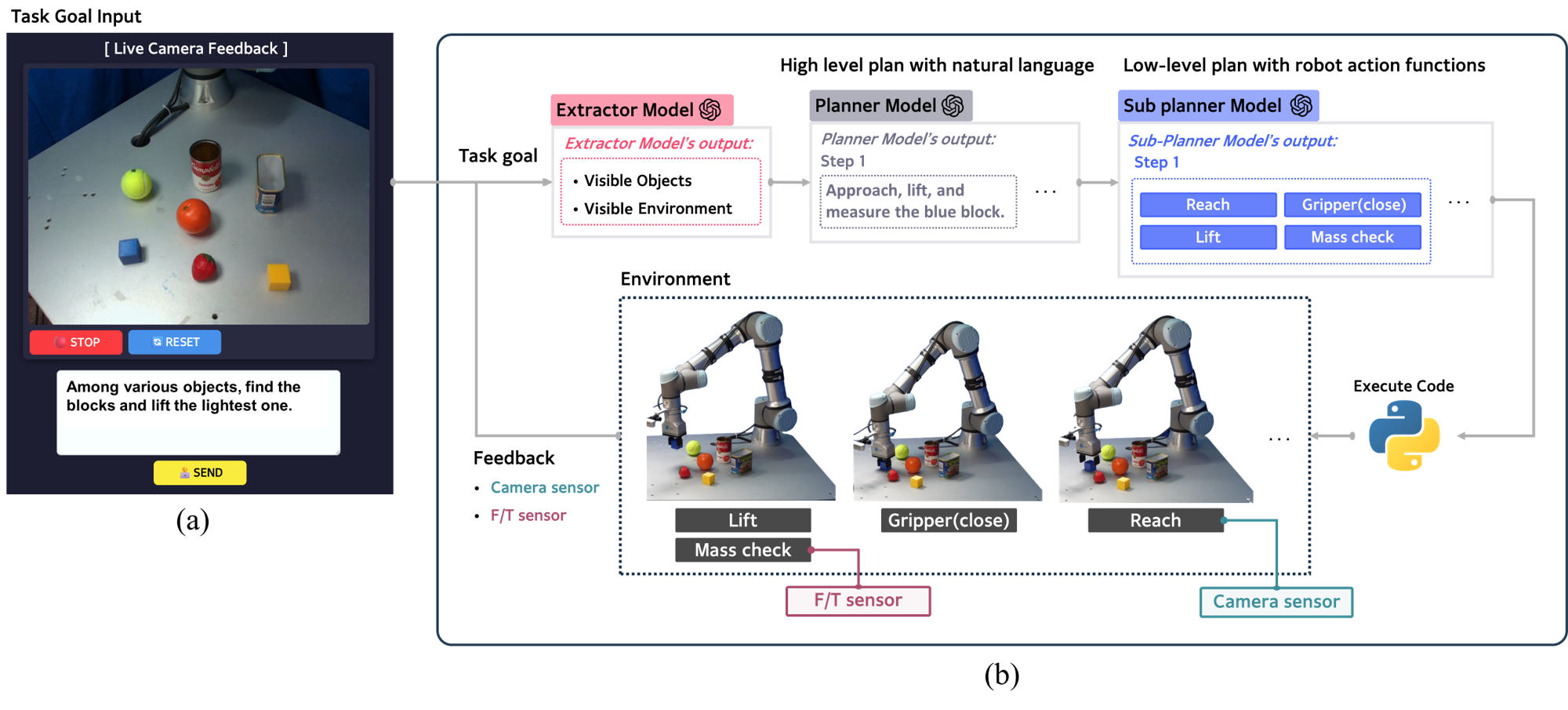
This study proposes a robot task automation framework based on large language models (LLMs) that utilizes both visual and physical information. The system integrates multimodal inputs, including camera images and force/torque (F/T) sensor data, to interpret the visual and physical state of objects and generate a task sequence to execute given commands. The integration of vision and force data allows the system to compensate for the limitations of each modality, leading to more reliable decision-making. The framework consists of three components: Extractor, Planner, and Sub-planner. According to their assigned roles, each agent automatically translates high-level commands given in natural language into executable robot motion plans, enabling the robot to perform the required sequence of actions. The system combines visual and force data to handle tasks that are difficult or infeasible with a single modality. Furthermore, it supports sequential and condition-based task planning through the collaboration of multiple LLM agents. Experimental results in various task scenarios show that the proposed framework operates reliably with different LLMs and achieves a higher success rate compared to using only visual or force data.
Framework
Citation
@article{turing1936computable,
title={On computable numbers, with an application to the Entscheidungsproblem},
author={Turing, Alan Mathison},
journal={Journal of Mathematics},
volume={58},
number={345-363},
pages={5},
year={1936}
}